Someone has just sent me a data breach. I could go and process the whole thing, attribute it to a source, load it into Have I been pwned (HIBP) then communicate the end result, but I thought it would be more interesting to readers if I took you through the whole process of verifying the legitimacy of the data and pinpointing the source. This is exactly the process I go through, unedited and at the time of writing, with a completely unknown outcome.
Warning: This one is allegedly an adult website and you're going to see terms and concepts related to exactly the sort of thing you'd expect from a site like that. I'm not going to censor words or links other than for privacy purposes; this is exactly what I go through during the verification process so you're going to get the whole thing, blow-by-blow.
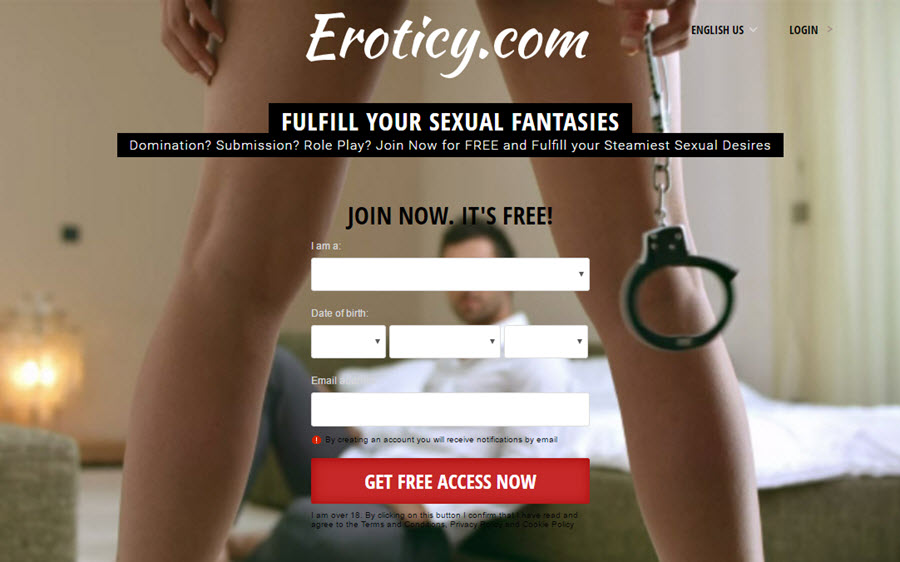
The file I've been sent is a 120MB zip called "Eroticy.com_June_2015.sql.zip". The sender of the file has said it's from eroticy.com and that's all I have to go on. I extract the file and find an 841MB MySQL script which I open up in Sublime Text which is pretty good at reading massive files:
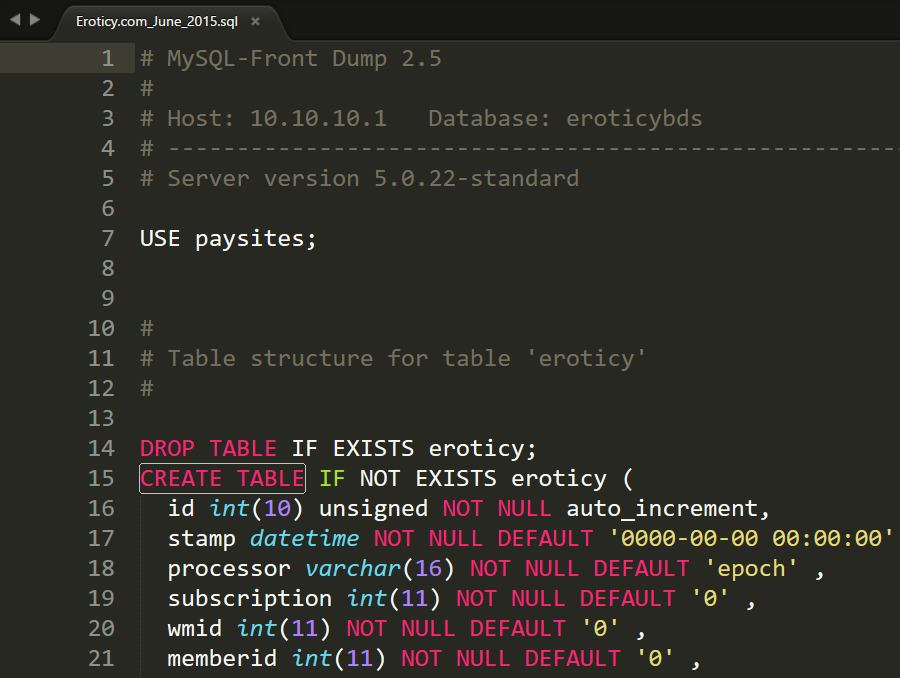
Ok, so a MySQL script file, fairly typical. I take a quick spin through and it's the usual trove of insert statements. I want a quick count of just how many email addresses are in the thing though so I point a little app I wrote at it to extract them all (it does some basic parsing and other checks):
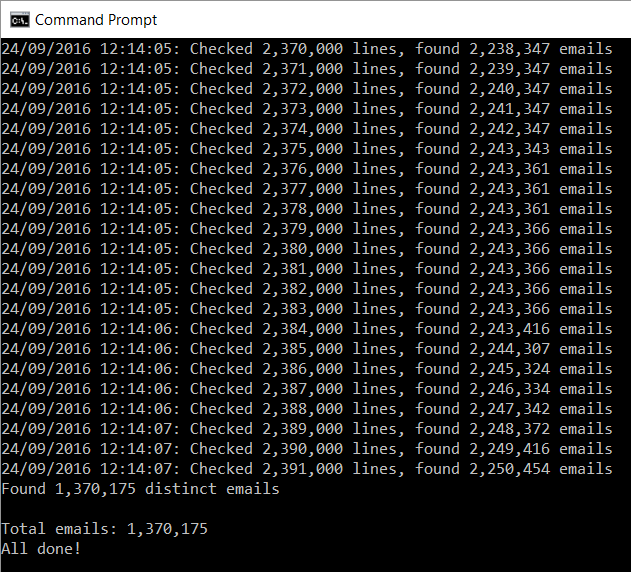
That's a sizeable result, nearly 1.4M unique email addresses (a bunch of them appear multiple times based on the output above). If it was small (say, under 100k records), I may not have bothered and moved onto something more sizable. It's pretty much the same effort for me regardless of size and bigger breaches impact more people so this helps me prioritise.
Time to check out the site, VPN and Incognito browser first thank you very much (probably make sure the kids aren't around too...):
Alright, so this is a bit volatile because it's not just a porn site, it's dealing with fantasies too which is really personal stuff. In fact, the site has redirected to dating.eroticy.com so it looks like it's designed to facilitate physical encounters. Let's see if I can easily tie the data to this site.
I go to the exported email addresses and grab a random Mailinator email address. I've written before about why these are useful and it's pretty much the first thing I do these days. Then it's off to the password reset form, but I begin by just fat-fingering the keyboard:
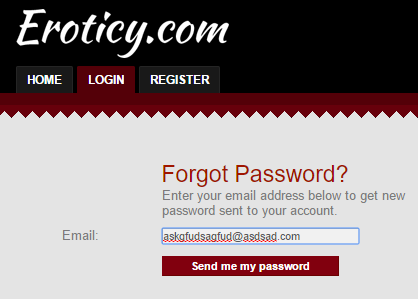
I want to see if the site has an enumeration risk which will confirm the address doesn't exist. Instead, the site responds as it should respond:
But by using a Mailinator address which the creator definitely knows is a public mailbox, I can then see if the mail is actually delivered. I submit it then check Mailinator:
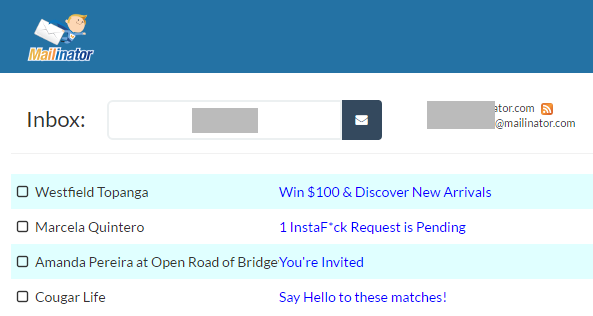
Huh, no email, but there's a definite pattern to the types of email the address has been receiving (although we all get plenty of porn spam). I try a few others and still no email. Normally about now I'd be seeing password reset emails and that would be enough to be pretty confident it's going to be a legit breach.
Let's try another enumeration vector:
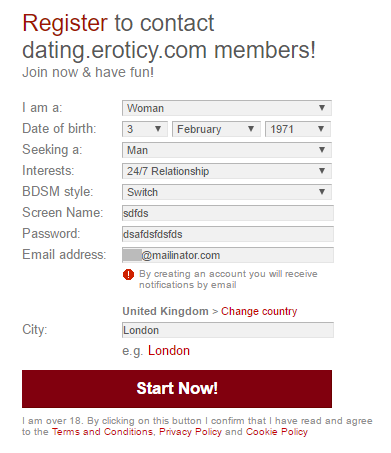
Most systems will tell you if the address already exists during registration. But here's what Eroticy does:
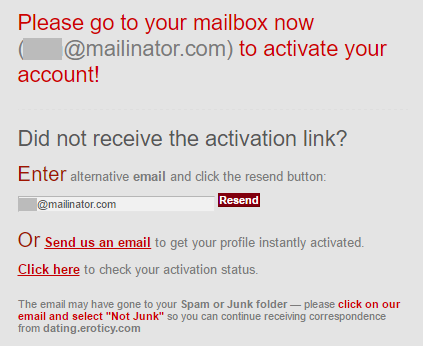
So either the account doesn't exist in the system or they're actively avoiding enumeration via registration. Checking Mailinator should tell me:
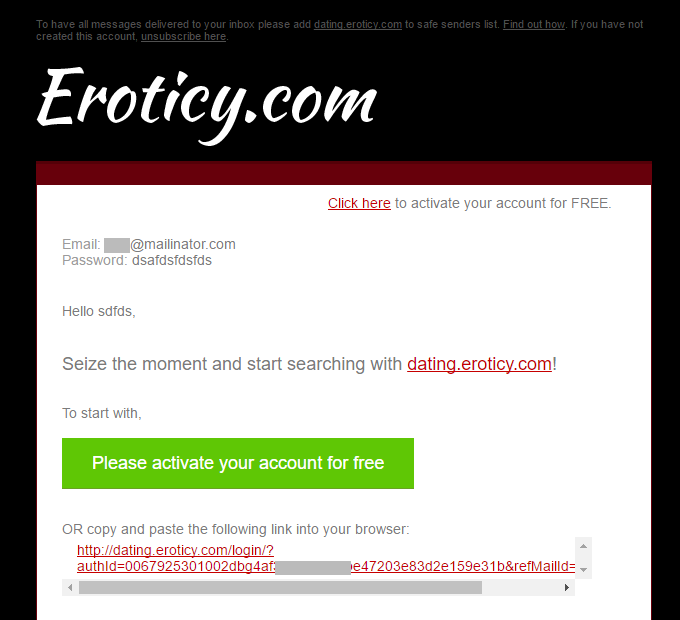
This is getting interesting. Looks like the account created just fine which is telling me that this address doesn't exist in their system already. I need to take a much closer look at the raw data because as it stands, as real as the data itself looks, no practical evidence is suggesting it came from Eroticy.
I do a bit of searching around too, including on vigilante.pw which has a pretty comprehensive list of alleged breaches. Eroticy is there:

I find other references in various other shady corners of the web too so at the very least, it's data that's been redistributed and branded as a breach. But none of it gives me any confidence it's actually legitimate in terms of the data actually having been sourced from Eroticy which is pretty much the point of going through this exercise here.
I want to be able to examine the data more thoroughly so I fire up a VM running MySQL and import the entire thing. This will make it easier to examine the schema as well as query the data.
While I'm waiting for the data to import, I look more closely at the raw statements within Sublime. I'm seeing a lot of URLs represented in there such as http://cartooncopulations.com/index.php/ft_15666_A_8a2b3c0c52d284c0ad8b604ec820cfac/ccoconsole1.html and http://monstrousmelons.com/index.php/ps_16568_A_6219246bcd03eda402719b3a68f3389b/main.html and a bunch of other far more explicitly titled domain names. The same domains appear many times over in a column called "ref" next to a date in a field called "day". Thing is, the dates are frequently in the 2004 era and a bunch of the domains are either dead or link to the same site with different branding:

The sites aren't explicit either - there's nothing you won't see on most beaches there - and they seem to be there primarily to drive traffic to other places.
The MySQL data is still loading so I look around the raw statements a little more. I find a table called EpochTransStats;
CREATE TABLE IF NOT EXISTS EpochTransStats ( ets_transaction_id int(11) NOT NULL DEFAULT '0' , ets_member_idx int(11) NOT NULL DEFAULT '0' , ets_transaction_date datetime , ets_transaction_type char(1) NOT NULL DEFAULT '' , ets_co_code varchar(6) NOT NULL DEFAULT '' , ets_pi_code varchar(32) NOT NULL DEFAULT '' , ets_reseller_code varchar(64) DEFAULT 'a' , ets_transaction_amount decimal(10,2) NOT NULL DEFAULT '0.00' , ets_payment_type char(1) DEFAULT 'A' , ets_pst_type char(3) NOT NULL DEFAULT '' , ets_username varchar(32) , ets_password varchar(32) , ets_email varchar(64) , ets_ref_trans_ids int(11) , ets_password_expire varchar(20) , ets_country char(2) NOT NULL DEFAULT '' , ets_state char(2) NOT NULL DEFAULT '' , ets_postalcode varchar(32) NOT NULL DEFAULT '' , ets_city varchar(64) NOT NULL DEFAULT '' , ets_street varchar(80) NOT NULL DEFAULT '' , ets_ipaddr varchar(16) NOT NULL DEFAULT '' , ets_firstname varchar(32) NOT NULL DEFAULT '' , ets_lastname varchar(32) NOT NULL DEFAULT '' , ets_user1 varchar(32) NOT NULL DEFAULT '' , PRIMARY KEY (ets_transaction_id), KEY idx_reseller (ets_reseller_code), KEY idx_product (ets_pi_code), KEY idx_transdate (ets_transaction_date), KEY idx_type (ets_transaction_type) );
It piques my interest because epoch seems like an usual name in this context so I give it a Google. That leads me to a page on a GitHub repository called Elite-Adult-Affiliate-Program. This is interesting because stuff is starting to line up: adult website, bunch of links to other sites and the schema containing a name that's represented in a project that seems to support adult site affiliate links.
There's another table in the dump called "console_links" so I search the GitHub repository for that but come up empty. But then I search for "EpochTransStats" and find a file called affiliateprogram.sql. There's a create statement in there for the EpochTransStats table and it has a heap of common columns:
CREATE TABLE `EpochTransStats` ( `ets_transaction_id` int(11) NOT NULL default '0', `ets_member_idx` int(11) NOT NULL default '0', `ets_transaction_date` datetime default NULL, `ets_transaction_type` char(1) NOT NULL default '', `ets_co_code` varchar(6) NOT NULL default '', `ets_pi_code` varchar(32) NOT NULL default '', `ets_reseller_code` varchar(64) default 'a', `ets_transaction_amount` decimal(10,2) NOT NULL default '0.00', `ets_payment_type` char(1) default 'A', `ets_username` varchar(32) default NULL, `ets_password` varchar(32) default NULL, `ets_email` varchar(64) default NULL, `ets_ref_trans_ids` int(11) default NULL, `ets_password_expire` varchar(20) default NULL, PRIMARY KEY (`ets_transaction_id`), KEY `idx_reseller` (`ets_reseller_code`), KEY `idx_product` (`ets_pi_code`), KEY `idx_transdate` (`ets_transaction_date`), KEY `idx_type` (`ets_transaction_type`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
Main difference with the breach data is that it doesn't have ets_country, ets_state and a few other columns. But still, there's way too much to be coincidental, there's a common origin there somewhere.
The data is finally up in MySQL, let's check out the schema inspector:
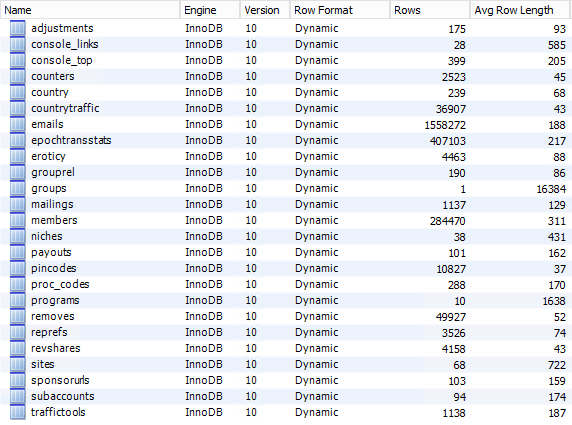
My eye is immediately drawn to the big one being the "emails" table with over 1.5M records so I check that out first:
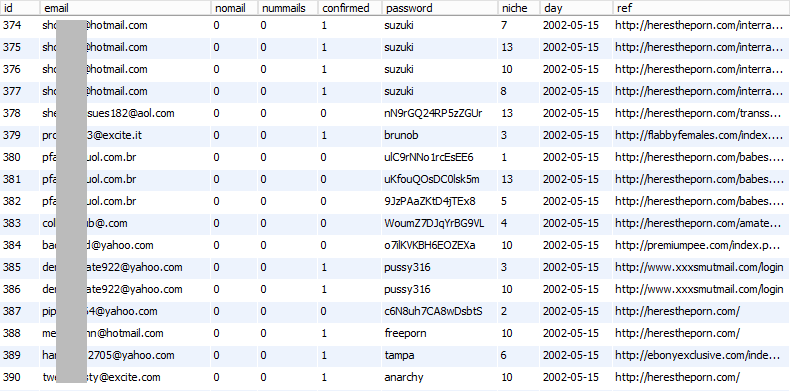
There's a few interesting things here:
- Lot of redundancy with the same email appearing multiple times over
- Password is different for the same email (i.e. rows 380, 381, 382)...
- ...but these almost certainly aren't all user passwords; there's too many good ones!
- The good passwords look system generated, but there are a heap of others which are clearly user generated
- The dates are very old - does this seriously go back as far as 14+ years?!
- The "ref" column is interesting, referrer from other sites, perhaps?
Some of these questions can be answered pretty emphatically, so I start querying the data:
- The earliest records are from 9 May, 2002
- The latest ones are from 31 Dec 2014 (that's a very wide range for a data breach)
I want to start actually reaching out to some of the people in this incident (which is always fun given the nature of the data...) so I start copying the email addresses I extracted earlier up into HIBP (this won't make them searchable on the site, it will merely give me the ability to query them). While that's running, I decide the "members" table is another particularly interesting one because it may actually start to point to individuals in the incident. Here's what I find in there:
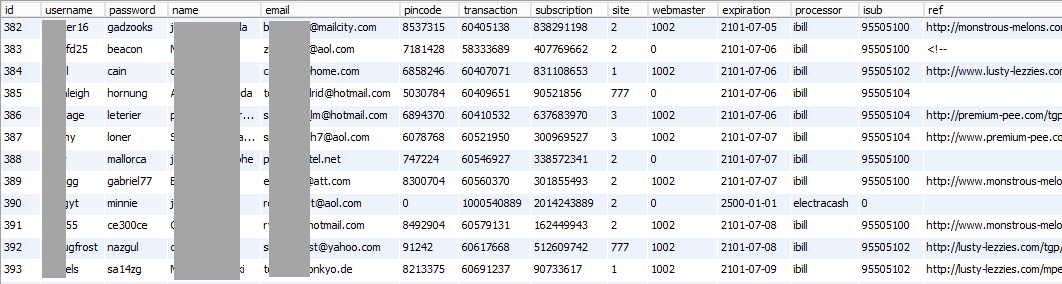
This gets more interesting because it looks like these folks have paid money for a service. We're seeing transaction numbers and payment processors here including iBill which Wikipedia describes as follows:
a top credit card transaction aggregator for adult entertainment websites
That article goes on to say that iBill was incorporated into another company and then changed names more than a decade ago, but a little further across in the set of columns beyond what I screen-capped above was another "day" column with dates as new as the last day of 2014. Some of these were processed by iBill. Turns out that iBill is a smaller player in all this though as I discover once I aggregate the processor column:
- epoch 199,414
- ccbill 40,684
- wts 26,250
- jettis 3,114
- ibill 2,536
- itrans 1,088
- electracash 356
- 2014charge 51
- psw 19
- wsb 18
Epoch has the lion's share of transactions and that's a potential avenue I could now go down to trace the source of the payments (I could always reach out to them). But at present, I'm still no closer to working out where the data actually came from though so I try a few queries:
select * from members where email like '%+%'People sometimes use the "+" syntax within email address aliases to identify the site they're using, for example test+eroticy@example.com which would imply the source of the data. There's zero results though which could be because some websites block the "+" symbol (don't do this guys!) but also because in my analysis of other breaches, I find there's usually only about 0.03% of accounts using this syntax.
I try another query:
select password, count(*) from members group by password order by count(*) descWhat I'm trying to do here is see if there's a commonly used password that might indicate the source (other than the usual generically crap ones). Here's the 50 most popular and their respective counts:
- 123456 1,525
- password 815
- pussy 301
- dragon 296
- 12345678 282
- football 236
- fuckme 234
- 696969 222
- qwerty 202
- baseball 200
- 12345 199
- 1234 196
- shadow 159
- 111111 156
- master 156
- letmein 156
- superman 153
- abc123 152
- monkey 145
- mustang 141
- jordan 131
- jessica 119
- 1234567 119
- fuckyou 117
- Harley 116
- michael 116
- hunter 113
- buster 111
- thomas 110
- ranger 102
- killer 102
- FUCK 101
- jennifer 99
- junior 97
- andrew 94
- asshole 94
- 666666 94
- tigger 94
- joshua 93
- batman 92
- ashley 91
- freedom 91
- 123456789 91
- amanda 86
- soccer 86
- bigdog 85
- h00ters 84
- ginger 82
- sunshine 82
- bandit 82
These are just the usual crap ones though with a bias towards what you'd expect on a porn site. I'm not seeing anything here that jumps out and indicates a potential source. Seeing a password such as "1234" though indicates a really weak password criteria on wherever it came from which is often a bit of an indicator of age (we had more tolerance for bad passwords years ago).
The email addresses are now in HIBP (not searchable in there, rather just sitting somewhere I can privately query them), and I find that of my 934k verified subscribers, 512 of them are in the addresses I extracted. I email the 30 most recent subscribers, the oldest having signed up 6 weeks earlier:
Hi, I’m emailing you as someone who has recently subscribed to the service I run, “Have I been pwned?” Your email address has appeared in a new data breach I’ve been handed and I’m after your support to help verify whether is legitimate or not. I’d like to be confident it’s not a fake before I load the data and people such as yourself receive notifications. If you’re willing to assist, I’ll send you further information on the incident and include a small snippet of your (allegedly) breached record, enough for you to verify if it’s accurate. Is this something you’re willing to help with? For verification, I’m on the about page of the site: https://haveibeenpwned.com/About
It'll take a while for people to start replying so I keep digging. The "payouts" table seems like an interesting name for an adult website:
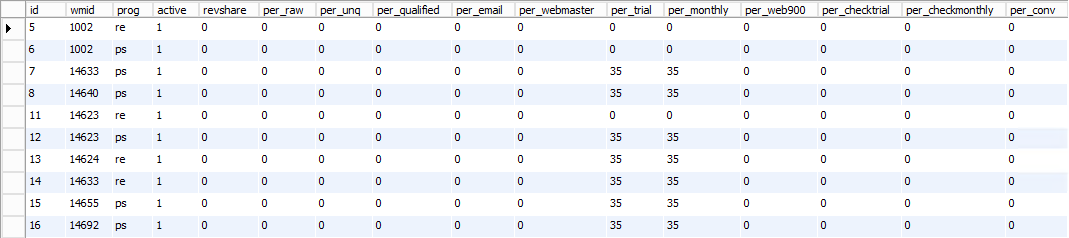
Seeing a column called "revshare" is making me think about the affiliate situation again as is the table name itself. Is this one of those deals where someone gets cash for enticing others to signup to a service? A "payout" based on "revenue share", perhaps?
A few responses from HIBP subscribers come in and I fire them back different variations of this:
This relates to a data breach which has allegedly come from the Adult website known as “Eroticy”. However, I don’t believe that’s the actual source of the incident due to various indicators in the data itself. I’m hoping HIBP subscribers can help me work out the actual source. Your email address is in the data, here’s what I can tell you about it, I’d appreciate your feedback on the accuracy of the data: 1. Your record says it was created on [redacted], however the data may be a decade older 2. There’s a password next to it of “[redacted]” (obviously I’ve obfuscated some characters here) 3. There is a “ref” column which I believe is for “referrer” and it has this value in it: [redacted] (the URL no longer has an active site on it) 4. There is an IP address of [redacted] which puts it in New York City: https://db-ip.com/[redacted] 5. There’s a username field of “[redacted]” 6. There’s a name field with “[redacted]” in it I know this is possibly more than a decade old, but does any of this look familiar? My suspicion is that a lot of the data could relate to affiliate programs within the adult entertainment space, if there’s anything you can share that might help me track down the source of this, it would be most appreciated.
One of the early responses is from a female which is pretty unusual as far as adult websites go. Her "ref" column has the site gangbangedgirls.com in it and I hesitate - momentarily - before sending her the info. What if she didn't actually sign up to it herself and I'm sending her what then appears to be an unsolicited link to a hardcore porn site? I figure I can always send her a screen cap of her record later on to clear myself if need be but admittedly, I did worry about how she'd react.
The responses from subscribers start coming in:
I think I signed up to that when I was researching how to develop an adult website. All that info is correct.
That's useful, he then continues:
I would call this 100% valid. I'd say it was maybe 7-9 years ago.
But when I pushed him on whether he recalled the name "Eroticy", he had no recollection of it although he did say that the "page design looks familiar".
Another subscriber chimed in:
That is a long time ago. Password sounds like something I would have used way back.
But then went on to say that he doesn't know what it would have been associated with.
The woman I mentioned earlier also responded, fortunately without any signs of me having offended her but echoing the previous response in terms of being unsure where the data would have come from:
This is not something I would have subscribed to at that time. the password, however is familiar.
And then more reassurance came through:
Ya that seems like something I probably made an account for back in the day when I was a kid. The password was definitely a BS one I used back then too.
Yet more confirmation of the legitimacy of the data itself came through:
That is - indeed - a non-secure password I used to use, and a username I've used - mostly on dating sites and other anon-ish environments where I don't want my more usual username to be immediately google-able. Some of the dating sites I was researching (honestly: I was paid to do it!) were almost certainly related to the adult entertainment biz. Also, I had an account on Xbiz a long time ago that almost certainly had that combination.
This is all great, but there's nothing in there that's helping me work out what's actually happened. And then this reply came in:
Yeah used to be an adult webmaster so there would be some of my data out there
So this isn't someone who's necessarily a customer, rather someone who's been involved in running these sites before. Further supporting that is I can't see him in either the "members" or "emails" tables like everyone else, he's actually in one called "webmasters" which had failed to import into MySQL. There's quite a bit of data in there about him and in fact it turns out he lives not too far from me. I send him all his data which he checks out and makes an observation very similar to my own:
That looks to be webmaster affiliate program table
Frankly, by now I'm starting to find myself at a bit of a loose end so I send him a link to this blog post in draft too. He provides some interesting feedback:
Epoch was THE processor. They had a couple of linux boxes sitting under a desk which were running the majority of transactions in the industry. Where you end up with multiple card processes is when the VISA rules start fining for chargeback ratios and processors start scrubbing cards aggressively. It was discovered that you could increase sales 25% by having multiple redundant processors in a chain, if one fails to accept the card you fall back to the next.
This is all very interesting in terms of the mechanics of how these sites work, but it's not getting me any closer to the source. (Interestingly, I've just finished reading Brian Kreb's Spam Nation and the whole premise of chargebacks is one the underground pharma industry had big issues with too.)
I decide the next step is to simply approach Eroticy about it. No, I'm not confident the data is from them but it's got their name on it and they're represented as having been hacked on other breach info websites so they've got a vested interest in investigating it. I plug this into their contact form:
Hi, my name is Troy Hunt, I'm an independent security researcher and you can find me at https://www.troyhunt.com Recently someone sent me data which was allegedly hacked from the Eroticy website. I'd like to draw this to your attention and provide you with information to help verify if indeed you've had a security breach. Could someone in a security or technical capacity please get in touch with me and I'll share as much as I can.
And that was successfully sent off:

And successfully received:
So now it's just a matter of waiting because short of their response, there's really nothing more I can do at this stage.
Except they didn't respond. I sent that off on the 2nd of Jan and 8 days later as I write this, there's nothing. Nothing in the inbox, nothing in the junk mail, nothing at all. In a way, this is kind of the end of the road in that there's not much more I can do. Yet on the other hand, what everything up until this point has demonstrated is that almost 1.4M people have their data floating around out there - their legit data - albeit with uncertainty as to the source.
Short of investing copious amounts of further time trawling through the data, there's one more avenue available here and it's a last resort, but it's worked in the past. I'm going to publish the data to HIBP and flag it as both "sensitive" (so it can't be publicly searched) and "unverified". I'm going to put Eroticy's name on it but clearly explain in the description of the breach that I couldn't verify them as the source, albeit that the data itself is accurate. Then I'll link through to this blog post so that people can get the whole story.
Here's what I'm hoping to achieve from this:
- People who find themselves in the data will be aware their info is circulating. Even without being able to confidently identify the source, this still gets those people thinking about where they're reusing passwords, how much info they're sharing publicly and other general measures they should be taking to protect themselves (i.e. not using their real email address on adult websites).
- This will be brought to Eroticy's attention and I'm more likely to get a response. At this stage, I can neither prove nor disprove that the data came from them. However, it's their name on the breach and you've got various data breach websites reporting that they've had an incident so it's in their best interests to take a position on this.
- By virtue of sharing as much information as I have here (yet obviously protecting the identities of those involved), I'm hoping that someone pops up and properly identifies the source of this. Maybe it'll be someone who worked on the system, ran an affiliate or even the person who originally bundled it all together and called it the Eroticy data breach.
I took a similar approach with Regpack a few months ago. The publicity the post garnered resulted in it taking all of a day and a half before they properly investigated and admitted that they'd been the source of the breach. I'm not sure if we'll see that in this case or not, but it will certainly get more eyeballs on the issue.
As of now, the data is searchable in HIBP but again, it's flagged as "sensitive". You cannot search for an email address via the public interface and get a hit on Eroticy, instead you need to use the (free) notification service which will send a verification email to the address and ensure the information is only visible to the owner of the address.
This is a long post that if nothing else, I hope demonstrates how abstract many of these data breaches can be and how much effort can go into properly verifying them. This was done over a period of more than 3 months in total, in part due to waiting on responses from people and in part due to having to fit a fairly arduous process into a busy schedule. If you've got ideas on the source, please leave your comments below and I'll add any noteworthy updates to the bottom of the post if and when they occur.



























. Shortcut: xkcd.com/now")